
始めに
medu4のテキストをPDFから文字データを抽出し、その文字だけでankiのデッキを作成しようと思い、試行錯誤を重ねたが、表からの文字データの抽出が難しいことや画像の扱いに困るなどの問題が生じた。
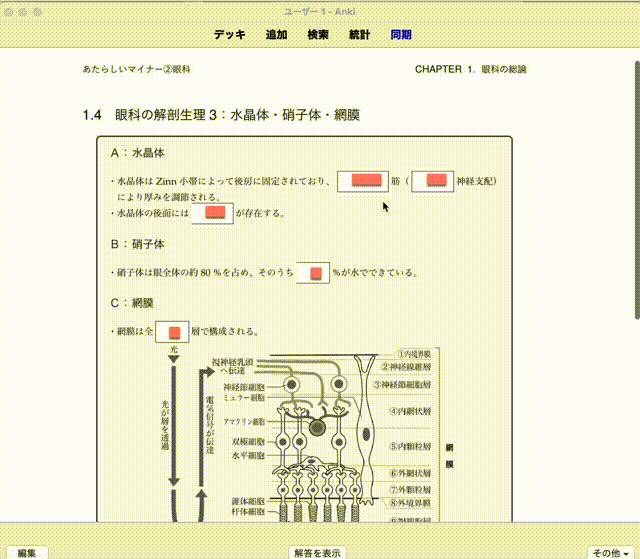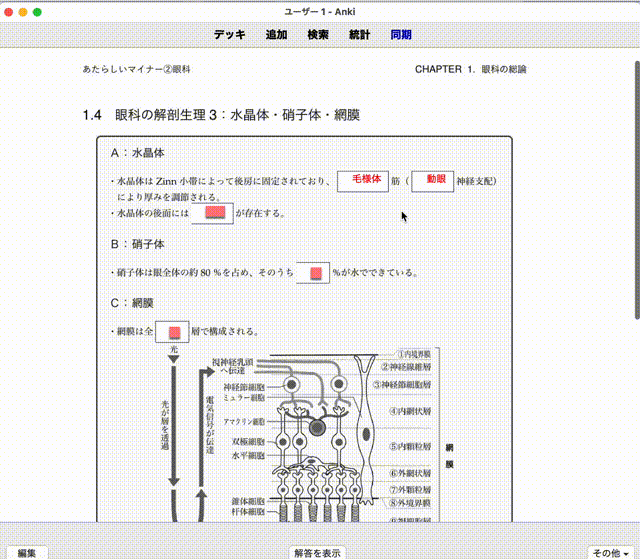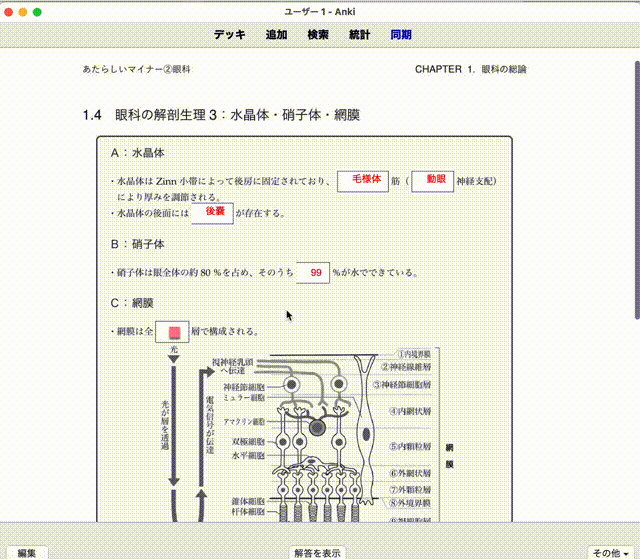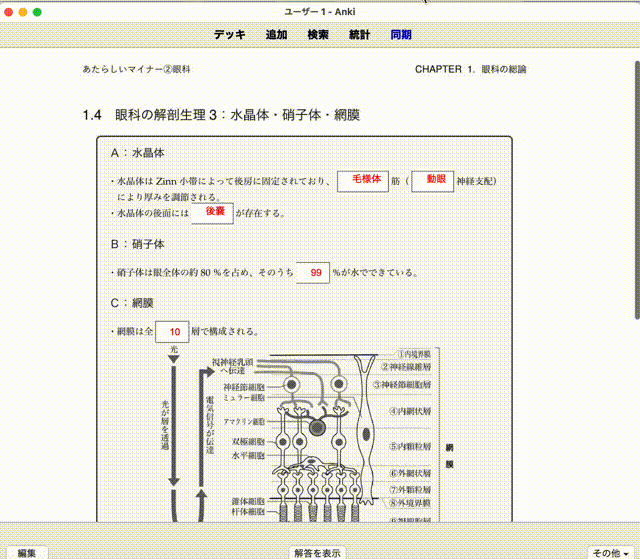
次に考えたのは、画像化したPDFの上に空欄になっている文字を位置情報を合わせて貼り付けることでこれはそこまで悪くない形になった。今回はその手法を説明しようと思う。
PDFの画像化
pdfの画像化はpdf2imageというライブラリを用いた。
文字の抽出
PDFにはどの環境でも互換性を維持したレイアウトで印刷可能となるように、文字とその位置情報が保存されているが、PDFからの文字情報を抽出するのは難しいものとなっている。
Python環境ではPDFから情報を抽出するライブラリとして、pdfminerやその派生版があり、今回はpdfminerの派生であるpdfmajorを用いた。これによって、文字の背景色が黒かどうかを判定し、黒でないものがあった場合、空白文字とみなして、その位置情報、文字、フォントサイズを取得している。
if not isBlack(ltchar.color.values):
if not is_searching_white_letter:
let = PDFLetter(x=ltchar.bbox.x0 + 2, y=ltchar.bbox.y0, fontsize=ltchar.size,letter=ltchar.get_text())
is_searching_white_letter = True
else:
let.letter += ltchar.get_text()
文字を画像に貼り付ける
次に、空白文字の座標を取得したことを利用して、以下のようなHTMLを自動生成した。この例では、毛様体や後嚢といった文字をPDFからx,y座標ごと抽出し、CSSのpositionプロパティにHTMLの座標系に変換した値を代入することで文字列の埋め込みを実現している。
<div class="test1"><img src="144531_2021gankaF_8.jpg"><div class="test2"><div style="position:absolute; left:55.24101202661208%; bottom:82.51024765705733%"><span class="cloze" onclick="cloze(this.id);">毛様体</span></div><div style="position:absolute; left:67.38549129989765%; bottom:82.51024765705733%"><span class="cloze" onclick="cloze(this.id);">動眼</span></div><div style="position:absolute; left:31.39297594677585%; bottom:78.62957440995855%"><span class="cloze" onclick="cloze(this.id);">後嚢</span></div><div style="position:absolute; left:48.51602482088025%; bottom:71.50096917649574%"><span class="cloze" onclick="cloze(this.id);">99</span></div><div style="position:absolute; left:25.499776100307063%; bottom:64.33613766644099%"><span class="cloze" onclick="cloze(this.id);">10</span></div>
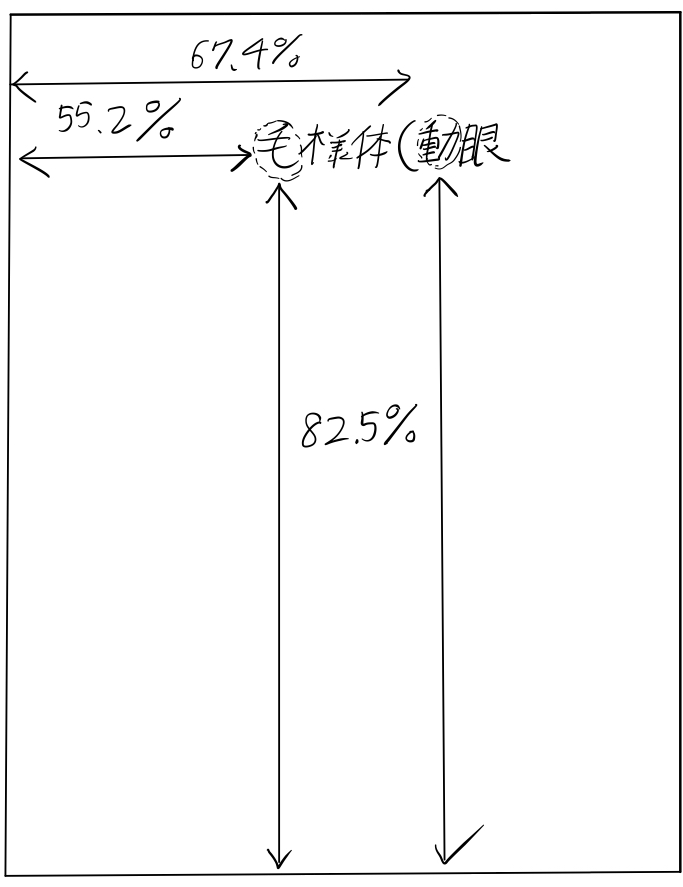
作成したもの
参考にしたもの
ankiで暗記ペンを実現する方法
https://ameblo.jp/macgyverisms/entry-12160265445.html
pdfmajor
https://pypi.org/project/pdfmajor/